| (二)物流需求指标:物流需求是指社会经济活动在物流的各个环节(如运输、仓储、配送、流通加工等)所提出的有支付能力的需要,是经济社会中的运行主体,为了满足其生产和生活的需要,而产生的对物流服务的需求。物流需求指标主要包括货运量和货物周转量论文开题报告。
(三)物流总量规模的指标:根据国家统计局和国家标准局1994年制定的国民经济行业分类标准,物流业属于第三产业中的交通运输、仓储及邮电业。因此,交通运输仓储邮电通信业生产总值能大致来反映物流总量规模。[27]
由于货物周转量指在一定时期内,各种运输工具运送的货物数量与其相应运输距离的乘积之和,[17]即货物周转量内涵着货运量与运输距离两个指标物流论文,同时,它和交通运输仓储邮电通信业生产总值也是紧密相关的。另外考虑到多重共线性,本文最终选取货物周转量作为衡量物流业发展水平指标。
四、实证分析:
(一)模型的设计
根据古典经济学的理论,决定产出的因素有固定资产投资、劳动力投入、自然资源和技术知识。在该理论的基础上,并借鉴江晓东,王丹的观点[28],本文认为物流在国内生产总值的增长的作用越来越大,一个国家或地区的物流能力也在相当程度上影响着产出,即产出的决定应该是如下函数形式:
 (1) (1)
采用科布-道格拉斯函数的形式,此时其表达式为:
 (2) (2)
其中, 表示产出, 表示产出, 分别表示固定资产投资和劳动力投入, 分别表示固定资产投资和劳动力投入,  (以 (以 来表示)为物流规模变量, 来表示)为物流规模变量, 为自然资源和技术知识变量。参数 为自然资源和技术知识变量。参数 、 、 、 、 、 、 、 、 代表弹性,且 代表弹性,且 , , , , , , 。 。
经过简单的数学变换,我们得到:
 (3) (3)
在短期内,我们假定:自然资源状况和技术知识水平保持不变。最终我们设定回归的计量模型为:
 (4) (4)
在进行参数估计时,以(4)式为基础,并采用面板数据(panel data)的分析方法,我们确定了对数模型(5)进行回归:
 (5) (5)
其中, 为被解释变量, 为被解释变量, 、 、 、 、 为解释变量, 为解释变量, 表示省(市、区)下标, 表示省(市、区)下标, ( ( 为横截面个数), 为横截面个数), 表示时间下标物流论文, 表示时间下标物流论文, ( ( 为时期数), 为时期数), 表示截距项, 表示截距项, 、 、 、 、 为待估系数, 为待估系数, 为随机扰动项。 为随机扰动项。
在建立面板数据模型时,首先必须检验所研究的问题应使用那种类型的面板数据模型进行研究:
假设1:斜率、、在不同的行业样本点和时间上都相同,但截距项 不同,即: 不同,即:
 (6) (6)
假设2 :截距项和斜率、、在不同的行业样本点和时间上都相同,即:
 (7) (7)
分别构造假设1的检验统计量: ;和假设2的检验统计量: ;和假设2的检验统计量: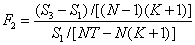 ;其中, ;其中, 、 、 、 、 分别代表模型(5)、(6)、(7)的残差平方和;为截面样本点个数,为时序期数, 分别代表模型(5)、(6)、(7)的残差平方和;为截面样本点个数,为时序期数, 为除截距项外的待估计参数(系数)个数。如果 为除截距项外的待估计参数(系数)个数。如果 大(等)于某一显著性水平下的同分布临界值 大(等)于某一显著性水平下的同分布临界值 ,则拒绝假设2;反之,利用模型(7)拟和样本。在已拒绝假设2的基础上,如果 ,则拒绝假设2;反之,利用模型(7)拟和样本。在已拒绝假设2的基础上,如果 大(等)于某一显著性水平下的同分布临界值 大(等)于某一显著性水平下的同分布临界值 ,则拒绝假设1,用模型(5)拟和样本;反之,用模型(6)拟合。 ,则拒绝假设1,用模型(5)拟和样本;反之,用模型(6)拟合。
(二)数据来源与变量的含义
由于2000年以前的统计数据严重不足,本文最终只能选取2001-2008年环珠三角地区(即:广东省的汕头、揭阳、潮州、汕尾、韶关、河源、清远、梅州、阳江、湛江、茂名、云浮十二个地市)相关的面板数据作回归(数据的年份短少导致无法做Granger因果性检验和协整分析)。计量所用最原始的统计数据均来源于各年度的《广东省统计年鉴》,各变量的含义如下:
 ——第市在第 ——第市在第 年的经济增长,这里用地区生产总值表示经济增长的变量。以各市地区生产总值指数作平减,折算为2004年(基期)的数值,单位为亿元; 年的经济增长,这里用地区生产总值表示经济增长的变量。以各市地区生产总值指数作平减,折算为2004年(基期)的数值,单位为亿元;
2/3 首页 上一页 1 2 3 下一页 尾页 |

