论文导读::应用于短信分类时。贝叶斯算法。短信的表示和特征提取。向量空间模型(VSM)。
论文关键词:短信分类,贝叶斯算法,特征提取,向量空间模型
1. 引言
随着移动通信技术的飞速发展和手机普及率的迅速提高,手机短信逐渐成为人们日常生活中不可或缺的通信方式,然而,由于其低廉的传输代价,使得我们每天收到很多不请自来的垃圾短信,一般来说,凡是用户没有定制过的包含有欺骗、色情、诅咒等内容并且是用外地手机或小灵通为发送号码的短信,均为垃圾短信[1]。垃圾短信的常见内容包括广告信息、色情信息、假中奖信息、欺诈信息、恶作剧等,垃圾短信危害社会安全、毒害社会风气、影响用户的正常生活,目前,垃圾短信过滤技术主要借鉴垃圾邮件过滤中的成果,如黑白名单过滤、规则过滤和基于关键词过滤等技术。
短信的主体内容仍然是由文本组成,因此对短信的分类就转化为对短信文本的分类,这里我们借鉴文本分类的过程对短信进行分类,分为正常短信和垃圾短信,并对不同类别的短信采取不同的处理办法。在文本分类算法中特征提取,贝叶斯方法拥有很多的优势,并且在垃圾邮件过滤方面取得了很好的成效。本文利用改进贝叶斯分类算法,对短信按照文本内容进行分类。通过实验验证,改进的贝叶斯短信分类器对垃圾短信和正常短信的识别率可以达到90.9%和98.2%。
2. 短信的表示和特征提取
2.1 向量空间模型(VSM)
计算机不能轻易地“读懂”短信内容,所以短信文本必须抽象为可在机器上计算的模型才可以进行分类,本文采用向量空间模型[2](Vector Space Model ,VSM)作为短信的表示模型,该模型的基本思想是用特征项来表示文本的语义,把文本表示成有权重的词为单位的项,项代表向量空间中的维度,权重代表维度的大小,每个文本被表示成一个n维向量,即短信文本Di可以表示为:
Di=(wi1,wi2,…,win) (式2-1)
式中,wij表示第j个特征项tj在短信Di中出现的频度(权重),n表示向量空间的维数中国论文网。可以看出,wij的值越大,表示tj越能反映短信Di所属类别,反之,该值越小,表示tj越不能反映短信Di所属类别。
2.2 特征提取
短信摘要对短信进行简单的预处理,然后根据特征提取方法提取有意义的特征项进行降维。本文采用文档频度(Document Frequency,DF)进行特征提取。
2.2.1 短信预处理
短信预处理主要包括以下步骤:
1、统一编码:统一为2字节的Unicode编码;
2、数字:连续的数字合并用“0”表示;
3、英文字母:连续的英文字母用字符“a”表示;
4、其它非汉字字符:用字符“b”表示;
5、分词:采用开源的ICTCLAS(Institute ofComputing Technology, Chinese Lexi-cal Analysis System)汉语分词系统,它是由中国科学院计算技术研究所在开发的基于多层隐式马尔科夫链模型的汉语词法分析系统, 该系统的主要功能有:中文分词、动态用户词典、新词识别、词性标注、未登录词识别等,分词精度98.45%;
6、停用词:根据“停用词表”对停用词进行过滤,用分词标志代替停用词。
2.2.2 文档频度(DF)特征提取
短信进行预处理并分词后,仍然存在大量的对分类没有大贡献的词语,且如果分类器的训练集短信数量较大时,其向量空间的维数仍然相当大特征提取,还必须对短信进行特征降维。特征选取[3]是指从原始特征空间中选择一部分重要的特征,组成一个新的低维空间。
常用的特征选取方法有:文档频度(DF),互信息(MI),信息增益(IG),χ2统计量等。由于一条短信的内容是有限的,本系统在特征选取算法上采用的是文档频度(DF)。文档频度是指在训练集中包含某个特征项的文本数目,认为中高频词对分类影响大,而低频词对分类的影响可以忽略不计,该方法先计算训练集中每个词的文档频度,然后根据预先设定的阈值排除那些文档频度特别低和特别高的特征项,保留中高频词用来表示文档。
2.2.3 权重的表示方法
特征项选取后就可以使用模型来表示文档了,在文本表示之前,还需要计算每个特征项的权重,使得重要的特征项权重大、不重要的特征项权重小。特征项权重的表示方法主要有:布尔权重、特征项频度、反文档频度、联合权重(TF-IDF)权重等,本实验系统中选择特征项频度作为权重的表示方法。
3. 贝叶斯算法
3.1 朴素贝叶斯(Na?ve Bayes)算法
贝叶斯方法[4]基于概率的一种算法,应用于短信分类时,通过计算短信属于正常短信和垃圾短信的概率,将其归为概率最大的一类;朴素贝叶斯方法是贝叶斯方法中最简单的形式,其原理是通过计算文本dx属于某个类别Cj的概率P(Cj|dx),把文本dx分类到概率最大的类别中。贝叶斯公式如式(3-1)所示:
 (3-1) (3-1)
 是类的先验概率, 是类的先验概率, 是类条件概率。设 是类条件概率。设 表示为特征项集合(t1,t2,…,tn),n为特征项个数,假设特征项之间相互独立,则、 表示为特征项集合(t1,t2,…,tn),n为特征项个数,假设特征项之间相互独立,则、 的计算方法为: 的计算方法为:
 (3-2) (3-2)
  (3-3) (3-3)
3.2 最小风险贝叶斯算法
朴素贝叶斯算法是基于最小错误率的决策方法,但在进行短信分类时,没有考虑到正常短信被错判为垃圾短信的风险,对用户来说,正常短信被判定为垃圾短信给用户带来的损失要大于垃圾短信的误判,为了解决这个问题特征提取,需要对朴素贝叶斯算法进行改进,在实验中我加入最小风险的贝叶斯决策中国论文网。
在短信的分类中,正常短信与垃圾短信具有不同的特征,基于最小风险贝叶斯短信过滤算法的决策表如表3-1所示:
表3-1 基于最小风险的贝叶斯决策
|
短信
|
正常短信
|
垃圾短信
|
|
正常短信
|
0
|
1
|
|
垃圾短信
|
k
|
0
|
由表3-1可以看出,当短信被正确判定时,不会给用户带来任何损失,其损失设定为0;垃圾短信被误判为合法短信时给用户带来的损失设定为1;合法短信被误判为垃圾短信时给用户带来的损失设定为k,根据前面的相对于用户来说,合法短信比垃圾短信更为重要,合法短信被误判为垃圾短信将可能给用户带来更大的损失,所以,k要远大于1。
3.3 改进的贝叶斯算法
短信过滤有一个非常重要的原则就是,错误过滤掉一条正常短信比错误过滤掉一条垃圾短信所产生的危害和损失要大得多,在朴素贝叶斯分类模型中,我们没有必要特意提高某个类别的识别率,而对于短信的分类来说,用户更加重视正常短信的正确识别率,基于这样的原则,我对贝叶斯分类算法进行了如下改进:
1、提高好词表中特征项的词频:
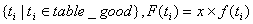 (3-5) (3-5)
 表示正常短信的特征项,即“好词表”中的特征项, 表示正常短信的特征项,即“好词表”中的特征项, 是特征项 是特征项 的原始词频, x表示增加的词频倍率, 的原始词频, x表示增加的词频倍率, 表示优化后的特征项词频,这样做的目的就是提高了正常短信中特征项的词频,x的取值应当大于1,但也不能取太大,如果过大会使得垃圾短信的误判率快速上升,实验时我进行了多种取值验证,发现x在1.5到2.5之间时,能够达到较好的效果,因此在训练分类器时选择x=2。 表示优化后的特征项词频,这样做的目的就是提高了正常短信中特征项的词频,x的取值应当大于1,但也不能取太大,如果过大会使得垃圾短信的误判率快速上升,实验时我进行了多种取值验证,发现x在1.5到2.5之间时,能够达到较好的效果,因此在训练分类器时选择x=2。
2、在好词表中增加未登录词:
 (3-6) (3-6)
未登录词指的是某特征项只出现在坏词表中,没有出现在好词表中特征提取,式中表示垃圾短信中的特征项,即“坏词表”中的特征项, 表示优化后的未登录词的词频,实验中我设置为词表中所有特征项词频的平均值 表示优化后的未登录词的词频,实验中我设置为词表中所有特征项词频的平均值 。 。
1/2 1 2 下一页 尾页 |

