摘要:基于构件的软件工程可以提高软件的质量,降低软件开发和维护的成本,构件的描述是构件检索和复用的基础,本文提出了一种基于向量空间模型的构件匹配方法,从而提高构件的查全率和查准率,从而改进了构件库的检索效率。
论文关键词:软件复用,构件库,向量空间模型
软件复用是一条提高软件生产效率和软件质量的切实可行的解决方案,其出发点是应用系统的开发以已有的工作为基础,充分利用已有系统的开发中所积累的知识和经验进行新的开发,这样软件开发的重点就可以集中于应用系统中的特有构成成分上[1]。软件构件只有在数量上达到了一定的规模才能真正满足软件复用和基于构件的软件开发的需求,因此软件复用很大程度上取决于可复用构件库。它作为一种对大量的软件构件进行管理的工具和支持软件复用的基础设施,它提供对软件构件进行描述、分类、存储和检索等功能。近年来,国内外研究人员分别从人工智能,关系学,信息检索等方法学上提出对构件的分类检索管理,其中在信息方法学中的刻面分类,枚举/层次分类等分类方法学上研究的相对较成熟[2],并且以这些技术为基础构建的构件库也都进入了试用阶段。但由于构件库可能会存放海量的构件和构件描述信息的复杂性,所以这些分类与检索方法在效率上仍然不能满足软件开发者的要求。
向量空间模型(vector space model,VSM)是由Salton及其学生们在20世纪70年代末到80年代初期提出并发展起来的[3],这一模型将给定的文本(文章、查询、或文章中的一段等)转换成一个维数很高的向量,它的最大特点是可以方便地计算出任意2个向量的近似程度,即向量所对应的文本间的相似性将所有文本和查询以向量形式表示,则针对特定的查询向量,比较它与所有文本向量的相似度,并依相似度将文本降序排列提交给用户,这便是现代信息检索系统中常用的方法[4]。本文把这种方法应用于构件库系统,从而,提高了构件的检索效率。
二 向量空间模型的基本概念
(1)文本(Document):泛指各种机器可读的记录,通常指一篇文章
(2)项(Term):也称为索引项或特征项或关键字当文本或查询的内容被简单地看作是由它所包含的基本语言单位(字、词、短语等)构成的集合时,这些基本语言单位统称为项VSM。假定存在一个项的集合,于是文本和查询均可用由项构成的向量来表示
(3)项的权重(Termweight):对于有n个不同的项的系统,文本 ,项tk(1≤k≤n)常常被赋予一个数值wk,表示它在文本中的重要程度,称为项tk的权重。因此,我们一般用 ,项tk(1≤k≤n)常常被赋予一个数值wk,表示它在文本中的重要程度,称为项tk的权重。因此,我们一般用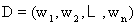 的形式表示文本。 的形式表示文本。
(4)向量空间模型:在有n个不同的项t1,t2, …,tn的系统中,给定文本 ,由于t1,t2,…,tn互不相同,我们可以把它们看作是n维欧氏空间n ,由于t1,t2,…,tn互不相同,我们可以把它们看作是n维欧氏空间n
基金项目:江苏省常州市科技计划项目项目资助(CQ2007005)
个坐标,而把看作是n维欧氏空间的向量。这样,我们称
为文本D的向量表示。
(5)相似度(Similarity):2个文本D1和D2的内容之间的相关程度(degree of relevance)通常用相似度来表示。在向量空间模型中,我们可以借助于向量之间的某种距离来表示文本间的相似度。通常用向量夹角余弦来计算。设 , ,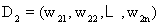 ,则夹角余弦公式: ,则夹角余弦公式:

三 基于构件描述的向量空间模型建立
在传统的文本检索中项的选取采用切词和系统自动选词作为矩阵的文本项,由于切词技术和选词技术具有较大的难度,因此,对于一般的文本检索,基于向量空间模型的检索并不能发挥它应有的优势。由于构件库中,对构件的文本描述的关键词相对固定,因此,在对构件文本描述建立矩阵的项也就相对比较固定。所以在构件库设计时,我们可以把那些相对固定的关键词作为矩阵的文本项,当然这些选中的关键词有着很大的不确定性,随时间的演进我们可以动态地增加和删除这些关键词。以某个关键词是否在构件描述中出现作为矩阵的项。
矩阵中各项可以是0,1,表示项在文本中是否出现,也可以用矩阵中的各项表示第 个词在第 个词在第 个文本中出现的频度。通常, 个文本中出现的频度。通常, 要考虑两方面的因素: 要考虑两方面的因素:
(1)局部权值 ,表示第个词在第个文本中的权重; ,表示第个词在第个文本中的权重;
(2)全局权值 ,表示第个词在整个文本库中的权重; ,表示第个词在整个文本库中的权重;
有一些改进权重的方法还考虑了文本在文本库中的权重。
这样 由下式求得: 由下式求得:

由于词和文本的数量很大,而单个文本中出现的特征项的个数是有限的,故文本/项矩阵 为高阶稀疏矩阵。 为高阶稀疏矩阵。
这样我们就把一个由m个文档n个关键词组成的一个文档库在向量空间模型(VSM)中表示成
 X.j代表一个词; X.j代表一个词;
X.i代表一个文档
四 基于构件的向量空间模型检索
当文本/项矩阵建立后,检索构件就是比较容易的事。我们可以把查询条件的文本作为一般的文本,提取项的值作为矩阵的一行。查询时,计算出查询条件对应的行向量与构件库中各个构件描述对应的行向量的夹角值,夹角值大小表示构件与查询条件的符合程度。一般情况下,我们选择夹角值最小的行对应的构件作为我们的查询结果。
1/2 1 2 下一页 尾页 |

