论文导读::可以借助VC实现对语音信号的采集。同时通过Matlab强。而MFCC则是构造人的听觉模型。本文用小词汇量的DTW方法。非特定人孤立词语音识别算法。
论文关键词:VC,Matlab,实时语音识别,MFCC,DTW,非特定人,MEX
1引言
VC和Matlab的混合编程共同运用于语音识别,可以借助VC实现对语音信号的采集,同时通过Matlab强
大的矩阵计算功能,简便化的编程方法,实现对语音
信号的识别处理。
其中,VC主要做语音信号的采集,通过借助于微
软提供的WindowsMultimedia API 开发了在线实时语
音采集程序,实现了人机在线实时交互。
2 语音识别系统概述
语音信号的一般处理过程如图 1所示,其中首先对语音信号进行预处理DTW,其中预处理包括预滤波、采样和量化、加窗、端点检测、预加重等。然后是信号特征量的提取,本文对信号的特征量进行Mel 频率倒谱系数(Mel-Frequency Cepstrum Coefficients)处理。最后通过对已经建立好的参数模板进行对比,测试的依据是失真度最小准测,如本文用到的动态时间规整: DTW(DynamicTime Warping)。

图 1 语音识别过程基本流程图
3 语音信号的采集
语音信号的两个过程为:对语音信号进行实时
的采集,对采集的语音信号做出识别。本文对语音信号的采集是通过VC调用Microsoft的Windows系统中提供了多媒体应用程序接口(Multimedia API)实现。
3.1 用VC生成动态链接库供Matlab调用
通过mex文件来实现VC与Matlab的混合编程。mex
代表 MatlabExecutable。Matlab中可以调用的C或
Fortran语言程序称为mex文件。mex文件是一种特殊的动态连接库函数,它能够在MATLAB里像一般的M函数那样来执行。
VC编译的时候应该包含头文件mex.h。与C中的主函数main()函数一样,mex程序中的开始函数为:
void mexFunction(int nlhs,mxArray *plhs[], int nrhs, const mxArray *prhs[])其中
nlhs指的是在调用函数时返回值的个数;
plhs[]是每个返回值(在MATLAB中都是矩阵)的指针;
nrhs指的是调用函数时的参数个数;
prhs[]是每个参数的指针。
对mexFunction的参数是进行指针操作的,不能用单纯的return返回值。mex程序传送回来的整数数据要变为双精度型数据,才能为其它函数所处理。
3.2 Multimedia API函数介绍
API(ApplicationProgramming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件的以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
MultimediaAPI 函数主要有以下几个:获取音频设备信的函数waveInGetNumDevs(),该函数用于获取当前系统中所安装的音频输入设备的数目。
查询音频设备的能力函数waveInOpen(),该函数的作用是打开波形输入输入设备。
通过CALLBACK_FUNCTION命令来打开设备。录音缓冲区的组织WAVEHDR结构, 一般都是设置双缓存区对语音信号进行平稳缓冲论文网站。开始和停止录音时用到waveInStart()和waveInStop()两个函数。
4 用Matlab实现语音识别过程
4.1 端点检测
从背景噪声中找出语音的开始和终止点这是在很多语音处理应用中的基本问题。端点检测对于语音识别有着重要的意义。本文主要采用短时能量与短时平均过零率双门限结合的方式,来对汉语语音的起止点进行检测。短时能量和过零率分别确定两个门限, 信号必须达到比较高的强度, 该门限才可能被超过。且低门限被超过未必就是语音的开始, 有可能是由短时间的噪声引起; 高门限被超过则可以基本确定是由于语音信号引起的。

 %每帧过零率 %每帧过零率
4.2 特征函数的提取
语音信号完成分帧处理和端点检测后,下一步就是特征参数的提取。目前在语音识别中较为常用的特征参数是线性预测倒谱系数(LPCC,LinearPredictive Cepstrum Coefficients)和Mel频率倒谱系数(MFCCDTW,Mel-FrequencyCepstrum Coefficients),这两种特征参数都是将语音信号从时域变换到倒频域上。LPCC从人的发声模型角度出发,利用线性预测编码(LPC,LinearPredictive Coding)技术求出倒谱系数,而MFCC则是构造人的听觉模型,把通过该模型(滤波器组)的语音输出为声学特征,直接通过离散傅立叶变换(DFT,DiscreteFourier Transform)进行变换。本文采用MFCC方法。Mel频率倒谱系数,即MFCC为:
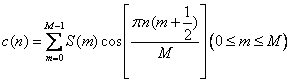
其中,S(m)为语音信号通过预加重、离散傅里叶变换、通过MEL滤波器、并通过对数能量处理等得到的对数频谱。
4.3 非特定人孤立词语音识别算法
通常,语音识别的方法可以大致分为三类,即模板匹配法、随机模型法、和概率语法分析法。这三类方法都属于统计模式识别方法。其中模板匹配法是将测试语音与参考模板的参数逐一进行比较和匹配,判决的依据是失真测度最小准测,随机模型法是使用隐马尔可夫模型(HMM,HiddenMarkov Model)来对似然函数进行估计与判决,从而得到相应的识别结果。而概率语法分析法利用连续语音中的语法约束知识来对似然函数进行估计和判决,更适用于大规模连续语音识别。本文用小词汇量的DTW方法。动态时间规整(DTW)是采用动态规划(DP,DynamicProgramming)技术,将一个复杂的全局最优化问题转化为许多局部最优化问题DTW,一步一步地进行决策。假设时间规整函数为: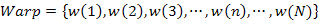 其中, 其中, 表示时间规整函数中的第 表示时间规整函数中的第 个匹配点对 个匹配点对
这个匹配点对是由待测语音的第个特征矢量和参考模板第 个特征矢量构成的,其中 个特征矢量构成的,其中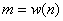 两者之间的距离(或失真值)称为局部匹配距离,记做 两者之间的距离(或失真值)称为局部匹配距离,记做 ,处于最优时间规整情况下两矢量的距离称为全局匹配距离,记做 ,处于最优时间规整情况下两矢量的距离称为全局匹配距离,记做 ,表达式如下所示: ,表达式如下所示:
由于DTW不断地计算两矢量的距离以寻找最优的匹配路径,所以得到的两矢量的匹配距离是累计距离最小的规整函数,这就保证了它们之间存在最大的声学相似特性。
5 结束语
在本语音识别系统中, 设定采样率为11025Hz,帧数为300帧,帧长为240点,则最长的语音段长度不会超过300*240/11025=6.5秒。采样样本为男女各5个人的数码语音资料, 实验表明, 系统达到了较好的实时性和较高的识别率。由于Matlab功能强大, 在处理中可直接利用许多现成的函数, 编程方便, 结果可视化也容易实现。
参考文献
[1]杨熙,苏娟,赵鹏.MATLAB环境下的语音识别系统[J].电声技术,2007,31(2): 51-53.
[2]龙银东,刘宇红,敬岚,等.在MATLAB环境下实现的语音识别[J]
|

