摘要:针对程序设计基础(C语言)网络课程的在线测试,开发了基于B/S技术的程序设计基础智能考试系统。利用了PBIL进化算法实现了组卷,很好的保证了试卷的结构、知识点、难度等属性的智能分配,设计了一个主观题评阅算法。
论文关键词:PBIL进化算法,智能考试系统
1 引言
随着计算机应用的迅猛发展,人们迫切要求利用现代信息技术来进行在线考试。在线考试系统极大地提高了教学的灵活性,它在许多领域已经有了广泛的应用。现阶段在线考试系统种类繁多,但目前已有的网上考试系统题型单一,没有真正通用的集自动组卷、在线答卷、自动评卷、成绩管理与统计分析、题库管理、用户管理、记录查询、在线审批于一体的综合考试系统,为了积极适应新形势的发展和信息网络化的发展趋势,科学有效地利用信息网络的资源和技术优势,开发一个在线考试系统是非常必要和可行的。
1.1国内外研究现状
目前大多数考试系统的系统结构:比较流行的是C/S结构和B/S结构。
C/S结构,即Client/Server(客户机/服务器)结构。它通过将任务合理分配到Client端和Server端,降低了系统的通讯开销。这种结构的考试系统要求在服务器和客户端单机上都安装考试应用软件,客户端软件具有考题的显示,考试计时及与服务器通信联络等功能。服务器端软件则负责维护题库、抽取试题及考后的阅卷、成绩的收取、统计、汇总等工作。考生在单机上参加考试,考试结果被系统收集到服务器中的指定目录下。
B/S结构,即Browser/Server(浏览器/服务器)结构。该结构的核心是WEB服务器,它负责接收浏览器的WEB页请求和数据请求,并处理WEB页请求,同时将数据请求通过数据库接口程序转换成数据库服务器能够接受的形式,之后送到数据库服务器,数据库服务器执行相应的数据库操作,并将结果通过数据库接口程序的转换送回WEB服务器,WEB服务器将结果处理成浏览器能够接受的形式后,送回发出请求的浏览器,显示结果。
2基于PBIL进化算法组卷
2.1算法的原理
PBIL算法基本原理[2]:设定S代表解的二进制编码,其长度为N,第i个基因位si(1≤i≤N)的取值为0或1,P=(p1,p2,p3,……,pn)代表一个N维的概率向量(Probability Victor),向量中各元素表示当前种群中的个体在对应基因位上不同取值时的学习概率;对于二进制编码的情况,pi(1≤i≤N)代表第i个基因位取值为1时的学习概率;r是算法的学习速率(Learning Rate ),M是种群规模。初始概率Pini中学习概率pi,大小都为0.5,即各基因位上取值为0或1的机会均等。
为了防止学习概率过早地收敛到0或1附近而产生早熟现象,在每一代对学习概率修正后,再按变异率P随机地选择部分学习概率pi进行调整,rm是变异速率(Mutate shift)。算法的处理流程[2]如下:
(1)初始化学习概率P:pi=0.5(1≤i≤N);
(2)由学习概率P指导随机产生M个个体;
(3)计算机由(2)产生的M个个体的目标函数值;
(4)根据(3)计算的目标函数值找出其中一个最优解:fitness;
(5)用(4)找到的最优解fitness修正学习概率P,修正方法如下:
pi= pi +(fitnessi- pi)×δ(δ为修正常数,1≤i≤N);
(6)对P进行变异操作;
(7)返回(2),直到满足结束条件为止。
2.2试卷结构分析
一份试卷一般涉及到总分、试题类型、试题类型分值、难度系数、各知识点分数分布等因素。以《C语言程序设计》为例,试题类型可分为填空题、选择题、程序填空题、写出程序运行结果和编程题。一般将难度划分为个四个等级(1,2,3,4级)。组卷算法就在以下几个方面尽可能接近目标值:
(1)试卷的总分应等于用户设定的总分,即:
 (1) (1)
其中n为试卷的题目总数,yi为第i个题目的分数,M为用户设定的试卷总分。
(2)各题型的总分之和应等于试卷的总分,即:
 (2) (2)
其中n为题型的总数,fi为第i个题型的分值,F为用户设定的试卷总分。
(3)试卷中同类知识点分数之和应等于用户要求的分数,即:
 (3) (3)
其中n为第k个知识点在试卷中的题目数量,zi为第k个知识点第i个题目的分数,Zk为用户设定的第k个知识点的分数,m为知识点的个数。
(4)各题型的分数应等于用户设定的分数,即:
 (4) (4)
其中n为第j个题型的题目总数,li为第j个题型中第i个题目的分数,Lk为用户设定的第k个题型的分数,m为题型总数。
(5)各题型的难度系数应等于用户设定的难度系数,即:
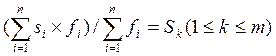 (5) (5)
其中n为第j个题型的题目总数,si为第j个题型中第i个题目的难度系数,fi为对应的分值,Sk为用户设定的第k个题型的难度,m为题型总数。
2.3目标函数
现用指标x1,x2,x3,x4,x5分别表示上述5项目标值。则可知,当x1,x2,x3,x4,x5越大时,说明目标值与用户要求的值相差越大;当x1,x2,x3,x4,x5越小时,说明目标值与用户要求的值相差越小;当x1,x2,x3,x4,x5等于0时,说明目标值与用户要求的值相等。再设各项指标的权重为:d1,d2,d3,d4,d5,它们反映对上述各项指示的重要程度。所以f=x1×d1+x2×d2+x3×d3+x4×d4+x5×d5表示整份试卷所有指示与用户要求的指示的相差程度。
下面定义各项指示的目标函数:
 (6) (6)
其中n为题目总分,yi为第i个题目的分数,M为用户设定的试卷总分a表示算法生成的最大误差。
 (7) (7)
其中n为题型的道数,fi为第i个题型的分值,F为用户设定的试卷总分,b表示算法生成题型的最大误差。
 (8) (8)
其中m为知识点的个数,n为第k个知识点在试卷中的题目数量,zi为第k个知识点在第i个题目的分数,Zk为设定的第k个知识点的分数,c表示算法生成的每个知识点分数的最大误差之和。
 (9) (9)
其中m为总题型数,n为第j个题型的题目总数,li为第j个题型中第i个题目的分数,Lj为设定的第j个题型的分数,d表示算法生成的每个题型分数的最大误差之和。
 (10) (10)
其中m为总题型数,n为第j个题型的题目总数,si为第j 个题型中第i个题目的难度系数,fi为对应的分值,Sj为设定的第j个题型的难度,e表示算法生成的每个题型难度系数的最大误差之和。综上所述,对于一个有M个个体,则总体目标函数表示为:
 (11) (11)
其中,i∈[1,M],M为种群规模,x1,x2,x3,x4,x5由以上目标函数决定,d1,d2,d3,d4,d5为该项指标的权重因子。
2.4组卷实现
题库中可以选取的试题的数量作为基因链的长度L,编码方式采用二进制编码方式。
1/2 1 2 下一页 尾页 |

