| 四、RD方法和城市圈
(一)RD方法的简介
Regression Discontinuity(RD)方法首先是由Thistlethwaite和Campbell(1960)提出的在非实验的情况处理treatment effects的一种方法,在使用RD方法的情况下,如果变量大于一个临界值时,经济个体接受treatment,而在该变量小于临界值时,经济个体则不接受treatment,由于经济个体在接受treatment的情况下,无法观测到其没有接受treatment的情况,而小于临界值的个体则可以作为一个很好的可控组(control group)来反映个体接受treatment和没有接受treatment时的差异,尤其是在变量连续的情况下,临界值附近样本的差别可以很好的反映treatment和经济结果之间的因果联系[12]。RD可以分为两类,第一类,临界点是sharp的,即在临界点一侧的所有的观测点都接受了treatment,反之,在临界点另一侧的所有观测点都没有接受treatment;第二类,临界点是fuzzy的,即在临界点附近,接受treatment的概率是递增的中国知网论文数据库。无论是哪一类,都可以利用临界点附近样本的系统性变化来研究treatment和其它经济变量之间的因果关系。Deaton(2009)认为在政策分析的实证方法中经济论文,最优选择当为随机可控实验(RCT),但是随机可控实验的时间成本和经济成本都比较高,而在随机可控实验不可得的情况下,应当考虑使用自然实验和工具变量的方法,而RD方法是仅次于随机可控实验的有效的利用自然实验约束条件的实证方法[13]。Lee(2008)也认为在随机实验不可得的情况下,RD方法能够避免参数估计的内生性问题以真实反映出变量之间因果关系[14]。然而,使用RD方法需要满足一定的条件,RD的有效性要求除了treatment以外的其它变量都是连续的,即E[Y0|X=d]和E[Y1|X=d]在boundary处是连续的,使用RD方法之前也需要检验所有其它变量在boundary内外没有系统性的变化,经济个体在boundary处不存在选择性的动机,同时控制变量也必须是连续的,并且不受到treatment的影响。虽然RD方法有着显著的优点,但是直到上世纪90年代末才被经济学家应用到处理经济学的问题,其主要应用领域为劳动经济学和政治经济学。
(二)RD方法在城市圈中的适用性
随着中国经济的发展,中国城市化进程也在不断加快,大量农村人口向城市转移,为了适应中国城市化的发展阶段,提高城市的影响力和发挥其集聚效应,促进经济增长和满足农村人口的就业,中国各个地区逐渐形成了若干城市圈,其中数东部地区的长三角、珠三角和京津冀三大都市圈区域经济发展总体水平高,各项经济发展总量指标占全国比重大,在国民经济中发挥着越来越重要的作用。长三角城市圈位于长江入海口及杭州湾,由上海城市群、南京城市群和杭甬城市群所组成,分别以上海、南京、杭州和宁波为中心城市,覆盖范围包括上海、南京、无锡、常州、苏州、南通、镇江、扬州、泰州、杭州、宁波、嘉兴、湖州、绍兴、舟山、台州16个地级市。珠三角城市圈包括广州、深圳、珠海、佛山、江门、中山、东莞、惠州和肇庆9城市,其覆盖范围沿广九线、广珠线两条轴线扩散。京津冀城市圈又被称之为 “首都圈”或“京津唐都市圈”,环渤海而建经济论文,该城市圈以北京为中心,包括天津、唐山、石家庄、保定、廊坊、秦皇岛、沧州、张家口、承德1个直辖市和8个地级市围合的半径200公里所覆盖的京津塘、京津保三角地区,土地面积约45000平方公里中国知网论文数据库。由此可见城市圈的划定范围基本是围绕着一个、几个中心城市或者重要交通枢纽,以中心城市或者交通枢纽为圆心,方圆多少公里之内均为城市圈的范围,因此,这种划分是以一个地区与中心地区的距离为基础,而距离又是一个连续的变量,因此城市圈的划分是适用于使用RD方法的。因此,城市圈范围的划分是周边地区与中心城市距离的函数,当周边地区与中心城市的距离大于临界值时,则该地区被划分在城市圈之外,而当周边地区与中心城市的距离小于临界值时,该地区被划分在城市圈之内。这种treatment只与距离有关,并且距离是一个连续变量,这种关系使得我们可以通过比较临界值附近的地区的经济绩效的差别来识别城市圈与地区经济绩效的因果联系。在图1中,距离大于城市圈边界的地区为城市圈范围,而小于城市圈边界的地区为城市圈之外,可以看到在临界点附近,地区的人均GDP都出现了间断的向上跳跃,这说明了城市圈内与城市圈外区域经济的绩效具有明显的区别。

注:各个样本值为距离5公里范围内地区的经济变量的平均值。
图1、城市圈内外区域经济绩效比较
五、计量模型与实证
(一)数据描述
本文选取了2007年中国京津冀、长三角、珠三角城市圈内县市的数据对中国城市圈经济绩效进行分析。本文的数据来源于国务院发展研究中心信息网(国研网),变量包括:人均GDP,用Pgdp表示;距离,为了得到距离指标,本文首先将根据城市圈的划定,将三大城市圈的边界确定,利用各个县市距离临界线的距离作为距离变量,城市圈外的为负值,城市圈内的为正值经济论文,用Distance(Dis)表示;耕地面积、电话使用数量和金融发展水平作为控制变量,分别用Farmland、Tel和Finance Dev表示,其中金融发展指标为存贷款之和与地区国民生产总值之比,之所以选择这些控制变量是因为耕地面积直接影响到农村居民的务农收入,电话使用数量也反映了并影响了地区发展的水平,金融发展则影响到企业的发展以及农业生产风险的规避,三者都影响到了地区性的总体收入。此外,还有一个虚拟变量Metro,它是Distance的一个函数,当Distance小于零时,Metro为0,当Distance大于零时,Metro为1。
为了说明RD方法的有效性,本文首先对主要变量进行描述,考察城市圈范围内和城市范围外的样本是否存在显著性的差异,其中下标表示个体,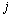 表示所属省份, 表示所属省份, 表示时间,其估计方程为: 表示时间,其估计方程为:
(1)
当Metro为0的时候,被解释变量的期望值为:
(2)
当Metro为1的时候,被解释变量的期望值为:
(3)
因此,方程(2)所得到的条件期望值即为城市圈范围外的样本均值,方程(3)所得到的条件期望值即为城市圈范围内的样本均值,由于,RD方法使用的一个前提要求除了treatment以外的控制变量要在临界值处连续,不能出现跳跃,表1的数据描述表明控制变量log(Farmland)、log(Tel)和Finance Dev变量在所有样本中,均没有出现显著的跳跃,这表明控制变量在临界值处没出现显著的跳跃情况经济论文,除此之外的其它的变量则在临界值处存在较显著的变化,这也说明了控制变量选择的合理性以及城市圈范围内外的经济绩效有出现差异中国知网论文数据库。
表1、数据描述
|
|
|
Full Sample(n=365)
|
|
|
|
Mean(Dis<0)
|
Mean(Dis>0)
|
Difference
|
|
|
|
|
Log(Pgdp)
|
9.29
|
9.9
|
0.61***
(0.06)
|
|
Log(Farmland)
|
10.32
|
10.36
|
0.04
(0.09)
|
|
Log(Tel)
|
11.63
|
12.78
|
0.15
(0.09)
|
|
Finance Dev
|
1.03
|
1.08
|
0.05
(0.04)
|
|
Distance
|
-80.49
|
43.58
|
124.07***
(4.89)
|
|
|
|
|
|
|
|
|
|
|
|Dis|<150(n=337)
|
|
|
|
Mean(Dis<0)
|
Mean(Dis>0)
|
Difference
|
|
|
|
|
Log(Pgdp)
|
9.34
|
9.91
|
0.57***
(0.06)
|
|
Log(Farmland)
|
10.3
|
10.36
|
0.06
(0.1)
|
|
Log(Tel)
|
11.6
|
11.76
|
0.16
(0.1)
|
|
Finance Dev
|
1.03
|
1.08
|
0.05
(0.04)
|
|
Distance
|
-63.11
|
41.47
|
104.58***
(3.92)
|
|
|
|Dis|<100(n=291)
|
|
|
Mean(Dis<0)
|
Mean(Dis>0)
|
Difference
|
|
Log(Pgdp)
|
9.38
|
9.93
|
0.55***
(0.07)
|
|
Log(Farmland)
|
10.3
|
10.37
|
0.07
(0.11)
|
|
Log(Tel)
|
11.59
|
11.82
|
0.23
(0.15)
|
|
Finance Dev
|
1.04
|
1.09
|
0.05
(0.04)
|
|
Distance
|
-47.03
|
34.87
|
81.9***
(3.12)
|
|
|
|Dis|<50(n=195)
|
|
|
Mean(Dis<0)
|
Mean(Dis>0)
|
Difference
|
|
Log(Pgdp)
|
9.42
|
9.89
|
0.47***
(0.08)
|
|
Log(Farmland)
|
10.33
|
10.328
|
-0.002
(0.13)
|
|
Log(Tel)
|
11.59
|
11.77
|
0.18
(0.13)
|
|
Finance Dev
|
1.04
|
1.08
|
0.04
(0.05)
|
|
Distance
|
-25.46
|
21.78
|
47.24***
(1.86)
|
注:括号内位标准差,*,**,***分别表示估计系数在10%,5%和1%水平显著。
(2)模型的初步估计
本文将计量模型的设定为:

其中 为控制变量,包括了Log(Farmland)、Log(Tel)和FinanceDev,为了避免因为模型设定不当而导致错误估计treatmenteffect的情况②,可以采取多种形式,但是为了使得分位数回归结果具有可比性,此处,采取了线性函数方式,模型(1)采取了一般最小二乘的估计方法,模型(2)是10%分位数的估计,模型(3)、(4)、(5)和(6)分别是25%分位数、50%分位数、75%分位数和90%分位数的估计。各个模型均包括了前文提及的控制变量,从估计结果可以看出,首先,无论是一般最小二乘估计,还是分位数估计,Metro的估计系数都是显著为正的,其估计系数范围为[0.172-0.381],这说明城市圈区域范围内的地区整体经济绩效要高于城市圈区域范围外的地区整体经济绩效,这与现有文献中的估计结果是一致的。其次,从模型的回归结果中可以看到,在10%分位数上,Metro的估计系数为0.172,按照增长率的换算公式,该系数变为0.188,这表明在其它控制变量不变的情况下经济论文,相比较与非城市圈地区,城市圈形成使得该地区人均GDP提高了18.8%,城市圈形成产生的辐射效应和政府治理结构变化带来的经济绩效增进要大于城市圈形成产生的集聚效应带来的负的经济绩效,明显低于一般最小二乘的估计结果,也小于其它分位数上的估计结果,25%分位数、50%分位数、75%分位数和90%分位数上的估计系数分别为0.315、0.381、0.338和0.246,按照之前的换算公式,在其它条件不变的情况下,相比较与非城市圈地区,处于这些分位数的地区人均GDP变化率在[0.279-0.464]之间,这说明发展水平较低的地区从城市圈形成中的获益要小于发展水平较高的地区。最后,25%分位数、50%分位数、75%分位数的估计系数要高于90%分位数和10%分位数的估计系数,这说明了城市圈形成后,发展水平较高的地区的增长效率要低于发展水平一般的地区的增长效率,但是要高发展水平较低的地区的增长效率,城市圈的形成过程中,受益最大的地区既不是发展水平较高的地区,也不是发展水平较低的地区,而是发展水平较为一般的地区,这一结论进一步阐明了城市圈的形成缩小了发展处于一般水平的地区与发展处于较高水平地区的收入差距,但是扩大了发展处于较低水平地区和其它地区的收入差距。 为控制变量,包括了Log(Farmland)、Log(Tel)和FinanceDev,为了避免因为模型设定不当而导致错误估计treatmenteffect的情况②,可以采取多种形式,但是为了使得分位数回归结果具有可比性,此处,采取了线性函数方式,模型(1)采取了一般最小二乘的估计方法,模型(2)是10%分位数的估计,模型(3)、(4)、(5)和(6)分别是25%分位数、50%分位数、75%分位数和90%分位数的估计。各个模型均包括了前文提及的控制变量,从估计结果可以看出,首先,无论是一般最小二乘估计,还是分位数估计,Metro的估计系数都是显著为正的,其估计系数范围为[0.172-0.381],这说明城市圈区域范围内的地区整体经济绩效要高于城市圈区域范围外的地区整体经济绩效,这与现有文献中的估计结果是一致的。其次,从模型的回归结果中可以看到,在10%分位数上,Metro的估计系数为0.172,按照增长率的换算公式,该系数变为0.188,这表明在其它控制变量不变的情况下经济论文,相比较与非城市圈地区,城市圈形成使得该地区人均GDP提高了18.8%,城市圈形成产生的辐射效应和政府治理结构变化带来的经济绩效增进要大于城市圈形成产生的集聚效应带来的负的经济绩效,明显低于一般最小二乘的估计结果,也小于其它分位数上的估计结果,25%分位数、50%分位数、75%分位数和90%分位数上的估计系数分别为0.315、0.381、0.338和0.246,按照之前的换算公式,在其它条件不变的情况下,相比较与非城市圈地区,处于这些分位数的地区人均GDP变化率在[0.279-0.464]之间,这说明发展水平较低的地区从城市圈形成中的获益要小于发展水平较高的地区。最后,25%分位数、50%分位数、75%分位数的估计系数要高于90%分位数和10%分位数的估计系数,这说明了城市圈形成后,发展水平较高的地区的增长效率要低于发展水平一般的地区的增长效率,但是要高发展水平较低的地区的增长效率,城市圈的形成过程中,受益最大的地区既不是发展水平较高的地区,也不是发展水平较低的地区,而是发展水平较为一般的地区,这一结论进一步阐明了城市圈的形成缩小了发展处于一般水平的地区与发展处于较高水平地区的收入差距,但是扩大了发展处于较低水平地区和其它地区的收入差距。
2/3 首页 上一页 1 2 3 下一页 尾页 |

