摘要:本文针对分布式电源接入配电网之后,如何协调分布式电源和配电网的关系,使分布式电源发挥最大能效,同时在配网出现故障,尤其出现孤岛运行时对配网产生的积极作用。提出基于G-MAS(Grover-Mutil Agent System)计及分布式电源的配电网络协调控制框架,使各个Agent在学习协作动作和选择输出以获得最优控制策略。最终达到对配网中DG协调控制,最大发挥DG作用,保证配电系统可靠、安全运行。
论文关键词:分布式电源,G-MAS,微网,配电网
随着DG并入配电网数量逐渐增多,配电网从原来辐射型单电源供电变成多电源共存模式。为配网能源多元化迎来机遇的同时,也给其安全、稳定运行带来了新的影响和挑战。由于分布式电源相对大电网来说是一个不可控的电源,所以,在电网出现事故导致孤岛运行时,往往遭到电网的限制和隔离的处置方式,以期减小其对大电网的冲击。这就分布式电源效能的充分发挥受到极大的限制。分布式电源和微电网由于采用就地能源,通过合理的规划设计,可以实现灵活供电,在灾难性事件发生导致大电网瓦解的情况下,可以保证对重要负荷的供电,并有助于大电网快速恢复供电,降低大电网停电造成的社会经济损失 [1-5]。
1 基于MAS的微网协调控制系统框架
本文建立基于MAS计及分布式电源的配电系统协调控制框架,如图1所示。从结构上分为四个层次,分别是配电网调度中心、微网控制中心、线路控制中心和单元控制器。由于微网所面临的用户负荷以及DG类型复杂[6]。
 图1 包含分布式电源的配电网协调控制系统 图1 包含分布式电源的配电网协调控制系统
在所建立的包含分布式电源的微网配电系统协调控制框架中,配网调度中心(总控Agent)负责配网内微网之间的宏观调控,微网和配网之间的协调处理,以及协调Agent负责协调配网与大电网之间的关系;微网控制中心(微网Agent)负责协调微网内各线路功率平衡;线路控制中心(线路Agent)负责协调线路中各DG Agent和负荷Agent以及储能电池组Agent之间的关系,保证系统最优控制[7-9]。协调控制框架中MAS通信系统如下图所示:

图2 MAS通信系统图
2 基于MAS的控制策略
2.1 配网控制中心(总控Agent)控制策略
配网控制中心(总控Agent)是协调各微网之间、以及配网和通过协调Agent大电网之间信息通信的核心。他与微网控制中心进行数据交换,时刻掌握微网的工作状态,以及通过协调Agent接受大电网的控制命令。以及对下一周期大电网运行的状态和整个配网状态进行估计。保证系统稳定、可靠运行的前提下,进行经济运行优化,并将优化结果下达到微网控制中心。系统运行时实现下列目标:
 (1) (1)
2.2 微网控制中心(微网Agent)控制策略
微网Agent理解和执行配网Agent下达的控制命令。同时将微网的运行信息线路上传信息进行综合、优化,并上传至总控Agent,进而实现:
 (2) (2)
微网工作状态有两种,即并网运行和孤岛运行。当并网运行时,根据总控Agent命令确定微网多余功率是否外送。当电力系统出现故障,配电系统出现孤岛运行时,微网Agent根据总控Agent指令,命令容量大的线路组织DG Agent满负荷运行,保证供电不间断。
2.3 线路控制器(线路Agent)控制策略
线路控制器(线路Agent)理解和执行微网下达的控制命令。同时将线路的运行信息以及对线路中的负荷和DG下一周期的运行状态进行预测,并上传至微网Agent,进而实现:
 (3) (3)
其中 为微网为线路提供的最小功率,当电网出现故障时,根据微网Agent下达的指令,甩掉普通负荷,同时实现 为微网为线路提供的最小功率,当电网出现故障时,根据微网Agent下达的指令,甩掉普通负荷,同时实现
 (4) (4)
保证线路重要负荷,和居民负荷的正常供应,确保居民的正常生活和重要负荷的电力供应。
2.4 单元(Agent)控制策略
单元控制器由于自身的特点,具有不同的自主性,并且特性也存在较大差异,如采用异步发电机作为接口的分布式电源会降低系统电压水平, 而燃料电池和同步发电机对系统电压具有支撑作用。
3 G-MAS算法的提出
本系统中MAS的典型应用采用分层控制结构,对整个配电系统进行集散递阶控制。它将整个系统分为决策层、组织层、协调层和响应层。每层均由完成相应任务的Agent组成。配电系统信息量大,数据繁杂,这直接导致MAS网络的特点是每个Agent都拥有其它Agent的大量信息和知识,这种端到端的通信效率必然是比较低的[10]。受Grover搜索算法的启发,在量子计算多Agent强化学习中,Agent根据他们的行为策略选择确定与之相关的量子算子,就可以利用量子纠缠态来协调他们的策略选择,最终获得最佳的平衡解。
量子位是量子信息的基本单位。一个量子位是一个双态量子系统,分别为 和 和 ,量子位可以是两个基态的叠加态。因此多Agent系统的学习是由n个共享一个量子位纠缠对的两个Agent之间小范围的学习组成的,每个Agent同时参与 ,量子位可以是两个基态的叠加态。因此多Agent系统的学习是由n个共享一个量子位纠缠对的两个Agent之间小范围的学习组成的,每个Agent同时参与  次小范围的学习,这样,每个Agent都可以在在不考虑空间距离和无通信的情况下同其他个Agent进行交互和策略的协调,最终获得全局最优策略的输出。因此,将多Agent协作学习中系统的状态和Agent动作用量子的叠加态表示,状态表示为: 次小范围的学习,这样,每个Agent都可以在在不考虑空间距离和无通信的情况下同其他个Agent进行交互和策略的协调,最终获得全局最优策略的输出。因此,将多Agent协作学习中系统的状态和Agent动作用量子的叠加态表示,状态表示为:
 (5) (5)
从状态到动作的映射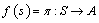 可以被表示为: 可以被表示为:
 (6) (6)
其中 和 和 分别表示状态 分别表示状态 和动作 和动作 的概率振幅。由于MAS中动作 的概率振幅。由于MAS中动作 是n个可能动作的叠加态,因此寻找最佳动作 是n个可能动作的叠加态,因此寻找最佳动作 跟在量子系统中改变他的概率振幅是相关的。我们不去搜索动作,而是更新的概率振幅。为了更新概率振幅,可以通过重复Grover操作L次强化高奖赏所对应的行为。初始的行为 跟在量子系统中改变他的概率振幅是相关的。我们不去搜索动作,而是更新的概率振幅。为了更新概率振幅,可以通过重复Grover操作L次强化高奖赏所对应的行为。初始的行为 可以被表述成 可以被表述成 ,而 ,而 。 。
1/2 1 2 下一页 尾页 |

